

1. Introduction
Dynamic memory allocation has always played an important role in software development. Real-time system applications allocate and deallocate memory quite frequently, affecting performance and fragmentation severely. Better performance and memory management can be obtained if applications manage their ‘own’ memory on real-time systems. This article discusses a faster and better dynamic memory allocation technique for real-time systems.
2. Techniques for Application-Level Memory Management
Before discussing the development of a C++ framework for memory management, here’s a background of the two common memory management techniques that are popular within the development community:
- Explicit lists
- Segregated lists
The C++ framework discussed here makes use of the segregated list mechanism.
2a. Explicit lists
Explicit lists generally have the memory region connected as a:
- Singly linked or a doubly linked list
- The list also can be circular
Figure 1 shows how contiguous heap regions are woven into singly linked lists. Occupied cells generally have a header placed at the beginning of the cell, followed by the actual ‘dynamic data’. The memory management system keeps a pointer to the ‘head’, the freelist. On getting a ‘malloc()‘ request (as in the case of ‘C/C++’ ) for an object of size X, the system will traverse through the ‘freelist’ to figure out a block of size Y, given Y >= X, where this object can fit in. The problem arises if Y is far greater than X. Typical memory management systems adopt a ‘best fit’ strategy where a ‘Y - X‘ value is reduced to the minimum, thus reducing fragmentation. The users also can opt for a ‘first fit’ strategy.
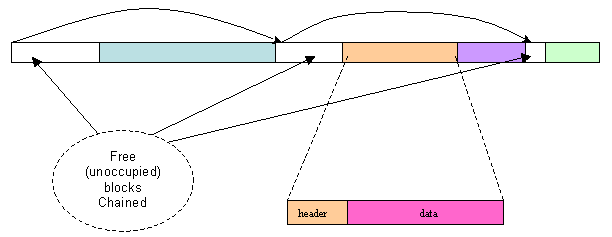
Figure 1: Explicit lists structure
Advantages:
- Bookkeeping is easy.
- Less memory is consumed for bookkeeping.
Disadvantages:
- Allocation and deallocation are much slower. The time required is not predictable.
- Coalescing of cells is difficult.
- Loops can result if not managed properly.
- General arithmetic is very complex.
2b. Segregated lists
Segregated lists are another mechanism in which there are different free lists for blocks of particular sizes. In this case, there are:
- Different free lists for blocks of different sizes
- Typically doubly linked
- Need header and footer for coalescing
- The links need not be in the same order as the blocks
![]()
Figure 2: Segregated Lists structure
Advantages:
- Less and fine grained fragmentation
- Allocation and deallocation faster
- Coalescing of cells easier
- Locating a free cell is easier
Disadvantages:
- Bookkeeping is difficult.
- realloc() is difficult.
The C++ framework discussed here uses the segregated list mechanism.
3. Segregated Lists
Any kind of memory management begins with a big chunk of contiguous memory and a free memory block. This free contiguous memory block has to be initialized first.
Initialization:
Initially, the free block would be as shown below. This free block is called the ‘free list’.
Figure 3: Free memory block (memory pool)
This big block is divided into smaller blocks. All small blocks are the same size and they are called cells or pages, of size say M.

Figure 4: Memory segmented into pages
Objects of size “less than or equal to” M/2 are packed into the same cell/page. That is, a page of size M can hold a maximum of 2 objects of size M/2 and a free cell/page can hold 4 objects of size M/4. To identify the “free block/cell” within a cell, a bitmap is used. An occupied cell is marked with a 1 and the one not occupied is marked with a 0. This can be easily noticed from Figure 5.
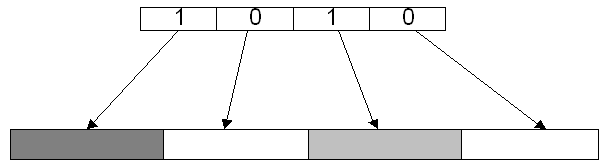
Figure 5: Bitmap indicating free or allocated block
In Figure 5, the shaded areas are the cells that have been occupied and the white ones aren’t occupied. Each block is of size M/4 within the cell. The inner cells are not restricted to just objects of size M/4. This statement means that the cells of size M/4 can hold objects of size X, where M/8 < X <= M/4, thus making it a completely binary arrangement.
Speed and response times are an important aspect of any real-time system. This would inadvertently mean that the memory management in real-time also has to be fast. Power of 2 (divide and conquer) algorithms are the most suited for attaining faster performances. The application level memory manager algorithm discussed here also uses a “power of 2” technique to achieve better performance.
3a. Segregated lists and binary arithmetic (buddy system)
In the algorithm that will be discussed here, all memory ‘allocations’ are categorized based on the size of the object, where the size of the objects falls with a range of powers of 2. For example, if the size of the object being allocated is. say. 35 bytes, the object will fall into the category where the objects are of size greater than 32 (2 ^ 5) and less than or equal to 64 (2 ^ 6).
Each page holds objects of one ‘category’, grouping objects into different categories. That is, if a an object of size ‘m‘ is allocated in a page P, such that i < m <= j (j = i+1), where i and j are some adjacent powers of 2, all the objects within that page would be of size p, where p = 2 ^ j.
For example, if the allocation request is for an object X of size “17” bytes, for this particular allocation request, the equation shown above translates to 16 < 17 <= 32, where i = 4 and j = 5 are the powers of 2 and m is equal to 17. All the objects in the category have the size ‘32‘ bytes, irrespective of whether they need 32 bytes or not. The page in which X is being stored would hold objects of size 16 < X <= 32 bytes. Any allocation request for an object of a different size that doesn’t fall into this range would go to a different page.
Objects that fall into the same ‘category’ are linked together using a separate chain as shown in Figure 6 below.

Figure 6: Data structures in segregated list
There will be a ‘head’ pointer that would point to the first page in the ‘category’ chain and there will be a ‘tail’ pointer that would point to the last page in the ‘category’ chain.