

My job involves moving different shapes and sizes of data linking systems and business processes together. Normally, I use Integration or Data Warehousing tools. Until I started using the Oslo SDK CTP “M” language, I’ve never considered building my own Domain Specific Language (DSL) as a tool in my repertoire.
If you’ve been following my Oslo SDK articles https://www.codeguru.com/columns/experts/article.php/c15779/, you’ve been introduced to MSchema, MGraph, and the Repository, all components of the Oslo SDK Modeling backbone. MGrammar is the third component in the “M” language. However, instead of defining data structure like MSchema, MGrammar defines data transformation, in particular, human-readable Text data transformation. Continuing to use the sample model I’ve developed in the other articles, I’m going to show you how MGrammer can be employed to populate Repository data.
Oslo Overview
Oslo is composed of the following components displayed in Figure 1.
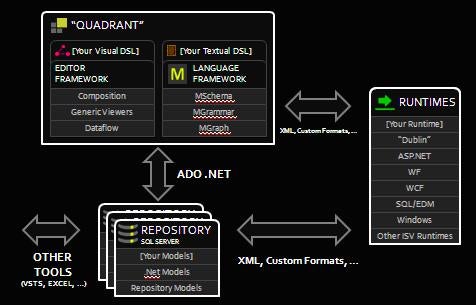
Figure 1: Oslo Architecture
Source: “Microsoft PDC 2008—A Lap Around Olso”
- “M”, a language for composing models
- The Repository, a SQL Server database designed for storing models
- Quadrant, a tool for editing and viewing model data
Currently, Quadrant is only available to PDC attendees. M and the Repository come with the Oslo SDK available on the Oslo Developer Center site http://msdn.microsoft.com/en-us/oslo/default.aspx.
Oslo’s goal is to deliver a foundation for building and storing models of all types. Models are application metadata formatted for runtime consumption. Separate Microsoft initiatives aim to build runtimes and tooling into applications such as Visual Studio that are Oslo model aware.
As I mentioned earlier, the M Language is composed of MSchema, MGraph, and MGrammar. A complete introduction to M is beyond the scope of this article. MSchema and MGraph were covered in my prior articles this article will acquaint you with MGrammar.
MGrammar Overview
Unlike XML, Text is a natural human-consumable data medium. Although text can be semi-structured like XML, text is not standardized like XML is. Parsing text to store it in, for example, a relational database using traditional development tools, though not difficult, is difficult to do right. MGrammar bridges the gap between plain human-readable, composable text data and XML, making semi-structured text parsing more approachable.
In a typical MGrammar program, a developer defines the patterns to search in the text and defines how the pattern is translated into MGraph. MGraph looks a lot like inline C# collections. Oslo utilizes MGraph to populate MSchema models in the Repository.
In MGrammar, a developer defines a set of Rules for transforming text into MGraph. MGrammar has three types of Rules:
- Token rules work and look a lot like Regular expressions
- Syntax rules can be composed of Tokens and define the MGraph produced from text input.
- Interleave rules define ignored text.
There are other features of MGrammar. However, a complete survey of the language is beyond the scope of this article and Rules are really the core of the language. So, I’m going to focus on Rules and, in particular, Token and Syntax rules. Using a sample, I’ll illustrate how some basic Token and Syntax capabilities are employed to parse text.
Sample Overview
The sample leverages the models I built in my prior article https://www.codeguru.com/columns/experts/article.php/c15779/. Model code snippets appear below.
type Requirement : Item
{
Description : Text?;
ApplicationId : Integer64;
}
Requirements : Requirement* where
item.ApplicationId in MyApplications.Id;
type ServerConfiguration : Item
{
Server : Text;
ApplicationId : Integer64;
}
ServerConfigInfo : ServerConfiguration* where
item.ApplicationId in MyApplications.Id;
Figure 2 depicts the sample application running in Intellipad, a development tool shipping with the Oslo SDK.
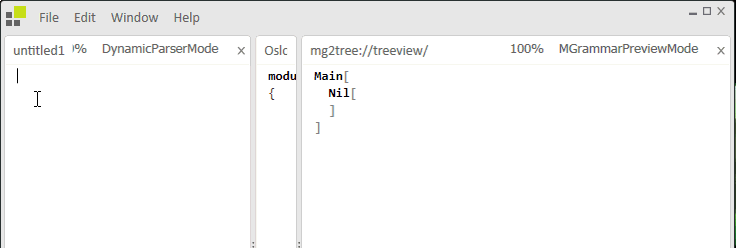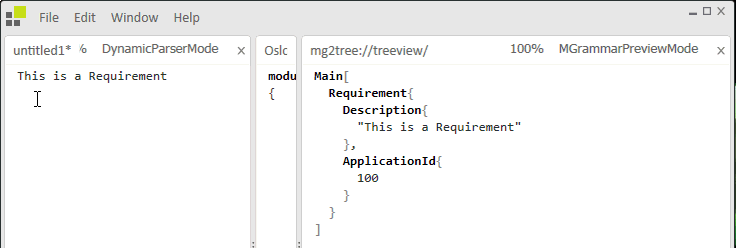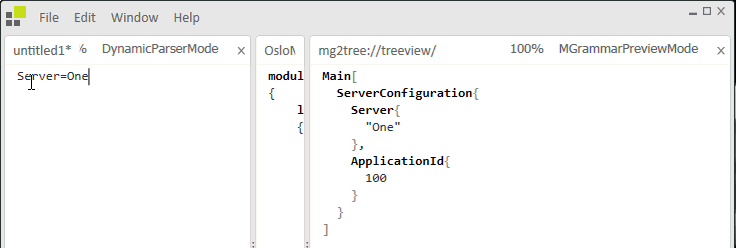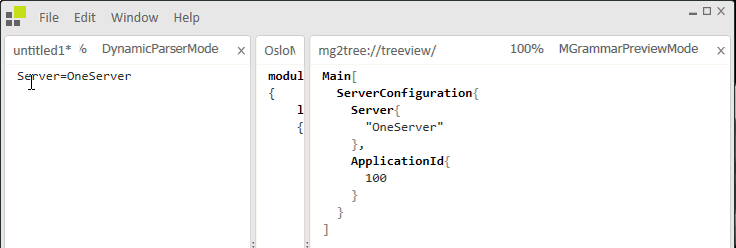
Figure 2: Application Execution
Enter a typical phrase and the text is translated to MGraph targeting the Requirement model. Enter Server and the application targets the ServerConfiguration model.
I’ve shown what the application does. Now, I want to show how it works.
MGrammar Structure
Following is the entire MGrammar sample.
module Sample.MGrammar
{
language ModelMGraph
{
syntax Main = Req | ServerConfig | Nil;
syntax Req = InputText:MultipleTextValues =>
Requirement { Description {InputText},
ApplicationId {100} };
syntax ServerConfig = "Server="
InputNum:MultipleTextValues =>
ServerConfiguration { Server {InputNum},
ApplicationId {100} };
//Case where nothing there without this there is an error
syntax Nil = empty;
token TextValue = "a".."z" | "A".."Z" | " ";
token MultipleTextValues = (TextValue)+;
}
}
As with other “M” programs, MGrammar applications are scoped to a module. Also like MSchema, MGrammar application can import and export libraries of Modules. As you can see, MGrammar supports comments and as I mentioned before the language syntax supports other things like, for example, preprocessor directives like #if and #define. Keep in mind, though, that the Oslo SDK is a CTP and MGrammar’s current incarnation is not complete. The Language keyword begins the application definition.
Main is the application entry point. Main must always be a Syntax. Text input into the MGrammar must match a defined Syntax or the application emits an error. In the example, there are three Syntaxes defining three distinct patterns: Req, ServerConfig, and Nil. Later in the article, I’ll explain how a Syntax is constructed. I want to start with the Tokens.
Token Rules
The Tokens in the sample application appear below.
token TextValue = "a".."z" | "A".."Z" | " "; token MultipleTextValues = (TextValue)+;
Tokens look and act a lot like Regular Expressions. Like Regular Expressions, Tokens can define patterns of text, numeric ranges, whitespace characters, and operators (&, |, *, +, etc.). Tokens can also include other Tokens.
In the example, TextValue defines a pattern containing any lowercase character, uppercase character, or space. MultipleTextValues defines a pattern matching one or more alphabetic characters.