

My previous article presented the XmlTextReader class and various code snippets that illustrated how to use it for sequentially reading XML documents or files, determining node types, and parsing for specific nodes and values. This week, I’ll cover a few more issues regarding the XmlTextReader class, including ignoring whitespace, skipping to content, and reading attributes.
Reading All Nodes
As a refresher—and for those who haven’t read the previous article—when reading an XML file using the XmlTextReader class, you are forced to read sequentially from the beginning of the file. Here’s a sample code snippet where all of the nodes of a specified XML file are read, with each node’s NodeType, Name, and Value property displayed:
// Simple loop to read all nodes of an XML file
try
{
String* format = S"XmlNodeType::{0,-12}{1,-10}{2}";
XmlTextReader* xmlreader = new XmlTextReader(fileName);
while (xmlreader->Read())
{
String* out = String::Format(format,
__box(xmlreader->NodeType),
xmlreader->Name,
xmlreader->Value);
Console::WriteLine(out);
}
}
catch (Exception* ex)
{
Console::WriteLine(ex->Message);
}
As you can see, the code simply instantiates an XmlTextReader object (passing it the file name to be read) and then calls the XmlTextReader::Read method until a value of false is returned. As each node is read, the NodeType, Name, and Value properties are then accessed. Figure 1 shows a screen shot of this article’s attached demo project, where all nodes are being displayed for the following file:
<?xml version="1.0" encoding="us-ascii"?>
<!-- Test comment -->
<emails>
<email language="EN" encrypted="no">
<from>Tom@ArcherConsultingGroup.com</from>
<to>BillG@microsoft.com</to>
<copies>
<copy>Krista@ArcherConsultingGroup.com</copy>
</copies>
<subject>Buyout of Microsoft</subject>
<message>Dear Bill...</message>
</email>
</emails>
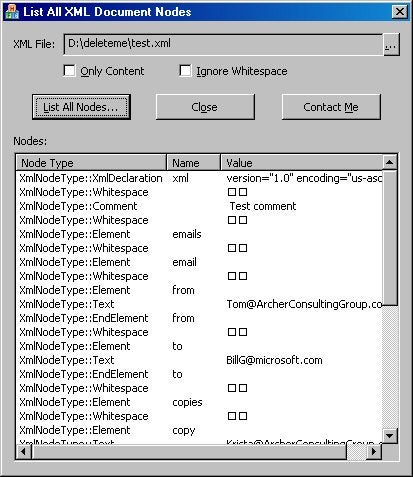
Figure 1: Displaying All Nodes of an XML File
As you can see in Figure 1, there are quite a few nodes that most applications will not care about the majority of the time. This includes things like the declaration node, comments, and whitespace. The next couple of sections show how to skip over these nodes so that your code can more efficiently concern itself only with nodes containing data (for example, element and text nodes).
Ignoring Whitespace
First, look at how to remove the whitespace nodes. The most obvious way of ignoring these nodes in your code is to insert a conditional statement in your read loop that ignores nodes of type whitespace:
// Ignore whitespace
if (xmlreader->NodeType != XmlNodeType::Whitespace)
{
...
}
Although this does work, it’s hardly efficient—especially with extremely large files. Therefore, the XmlTextReader class provides a property called XmlTextReader::WhitespaceHandling that is of type WhitespaceHandling that allows you to specify how you want to deal with whitespace. The valid values are:
- All
- None
- Significant
The All and None enum values refer to either wanting all whitespace nodes (the default) or no whitespace nodes, respectively. The Significant value refers to nodes of type SignificantWhitepsace, which are returned only within the an xml_space=’preserve’ scope.
To specify that your code does not need to read any whitespace nodes, simply set this attribute accordingly:
// Ignore whitespace xmlreader->WhitespaceHandling = WhitespaceHandling::None; // read loop
Figure 2 shows the demo application with whitespace nodes ignored.
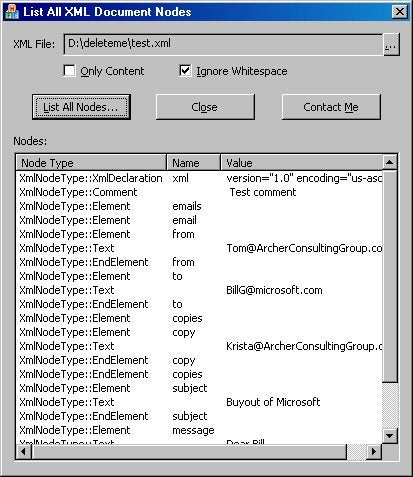
Figure 2: Ignoring Whitespace Nodes