

By Raymond Roestenburg, Rob Bakker, and Rob Williams
This article was excerpted from the book Akka in Action.
A cluster is a dynamic group of nodes. On each node is an actor system that listens on the network. Clusters build on top of the akka-remote module. Clustering takes location transparency to the next level. The actor might exist locally or remotely and could reside anywhere in the cluster; your code doesn’t have to concern itself with this. Figure 1 shows a cluster of four nodes.
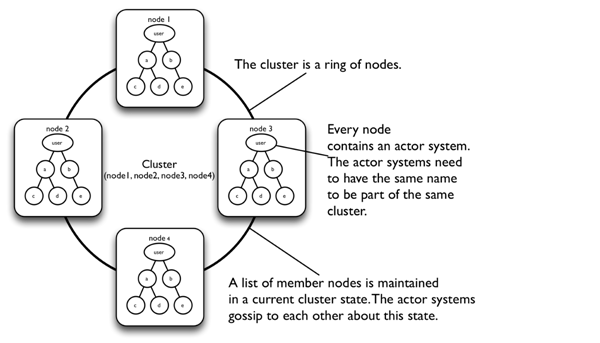
Figure 1: A four-node clustered actor system
The ultimate goal for the cluster module is to provide fully automated features for actor distribution, load balancing, and failover. Right now the cluster module supports the following features:
- Cluster membership: Fault tolerant membership for actor systems.
- Load balancing: Routing messages to actors in the cluster based on a routing algorithm.
- Node partitioning: A node can be given a specific role in the cluster. Routers can be configured to only send messages to nodes with a specific role.
- Partition points: An actor system can be partitioned in actor sub-trees that are located on different nodes. Right now only top-level partition points are supported. This means that you can only access top level actors on nodes in the cluster using routers.
Although these features don’t provide everything we need for a fully location-transparent cluster (like automatic rebalancing, repartitioning, and replication of state), they do provide the means to scale applications dynamically. You can be sure you’ll find features for most of these missing items in future versions of Akka or as part of extensions contributed to Akka.
A single-purpose data processing application is a good example of a candidate application for using clusters right now, for instance data processing tasks like image recognition or real-time analysis of social media. Nodes can be added or removed when more or less processing power is required. Processing jobs are supervised: if an actor fails, the job is restarted and retried on the cluster until it succeeds. Figure 2 shows an overview for this type of application.
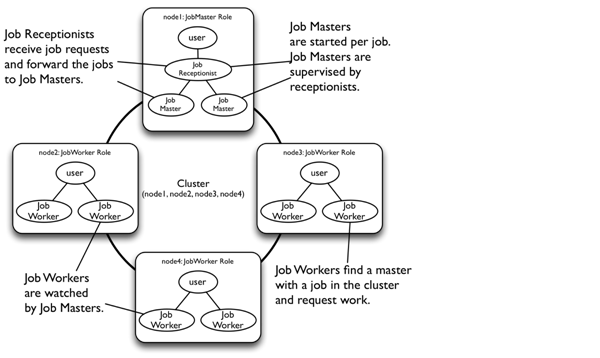
Figure 2: Processing jobs
Let’s move on to writing the code to compile our clustered word count application. In the next section, we’ll dig into the details of cluster membership so that the job masters and workers can find each other to work together.
Cluster membership
We will start with the creation of the cluster. The processing cluster will consist of job master and worker nodes. Figure 3 shows the cluster that we are going to build.
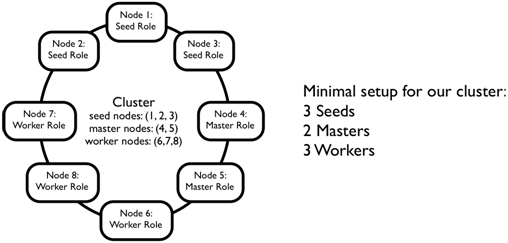
Figure 3: Word-counting cluster
The job master nodes control and supervise the completion of word-counting jobs. The job workers request work from a job master, process parts of the text, and return the partial results to the master. The job master reports the result once all word counting has been done. A job is repeated if any master or worker node fails during the process.
Figure 3 also shows another type of node that will be required in the cluster, namely seed nodes. The seed nodes are essential for starting the cluster. In the next section we’ll look at how nodes become seed nodes, and how they can join and leave the cluster. We’ll look at the details of how a cluster is formed and experiment with joining and leaving a simple cluster using the REPL console.
Joining the cluster
Like with any kind of group you need a couple of “founders” to start off the process. Akka provides a seed node feature for this purpose. Seed nodes are both the starting point for the cluster, and they serve as the first point of contact for other nodes. Nodes join the cluster by sending a join message which contains the unique address of the node that joins. The Cluster module takes care of sending this message to one of the registered seed nodes. It’s not required for a node to contain any actors, so it is possible to use pure seed nodes. Figure 4 shows how a first seed node initializes a cluster and how other nodes join the cluster.
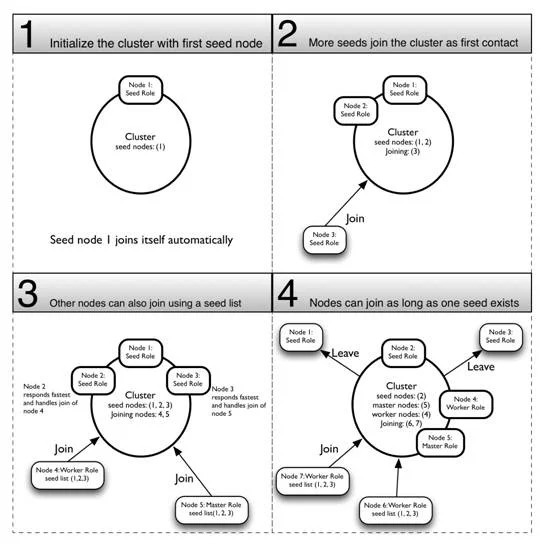
Figure 4: Initializing a cluster with seed nodes
Cluster does not (yet) support a zero-config discovery protocol like TCP-Multicast or DNS service discovery. You have to specify a list of seed nodes, or somehow know the host and port of a cluster node to join to. The first seed node in the list has a special role in initially forming the cluster. The very next seed node is dependent on the first seed node in the list. The first node in the seed list starts up and automatically joins itself and forms the cluster. The first seed node needs to be up before next seed nodes can join the cluster. This constraint has been put in place to prevent separate clusters from forming while seed nodes are starting up.
| SIDEBAR |
Manually joining cluster nodes The seed nodes feature is not required: you can create a cluster manually by starting a node that joins itself. Subsequent nodes will then have to join that node to join the cluster, by sending it a Join message. This means that they will have to know the address of the first node, so it makes more sense to use the seed functionality. There are cases where you can’t know IP addresses or DNS names of servers in a network beforehand. In that case, there are three choices that seem plausible:
Mind you, a Zookeeper solution will still require a full set of host and port combinations, so you are trading in one well-known set of addresses for another. This is also not as trivial as it sounds since you have to keep the discovery service up to date on the availability of every cluster node, and the discovery service might depend on a different set of trade-offs than Akka cluster, which might not be apparent immediately. Caution is advised. (Different consistency models will probably apply and your mileage may vary on experience in identifying these trade-offs.) |
The seed nodes can all boot independently as long as the first seed node in the list is started at some point. A subsequent seed node will wait for the first node to come up. Other nodes join the cluster through any of the seed nodes once the first node is started and at least one other node has joined. A message is sent to all seed nodes; the first seed node to respond will get to handle the join command. The first seed node can safely leave the cluster once the cluster has two or more members. Figure 5 shows an overview of how a cluster of masters and workers can be formed after at least the first seed node has started:

Figure 5: 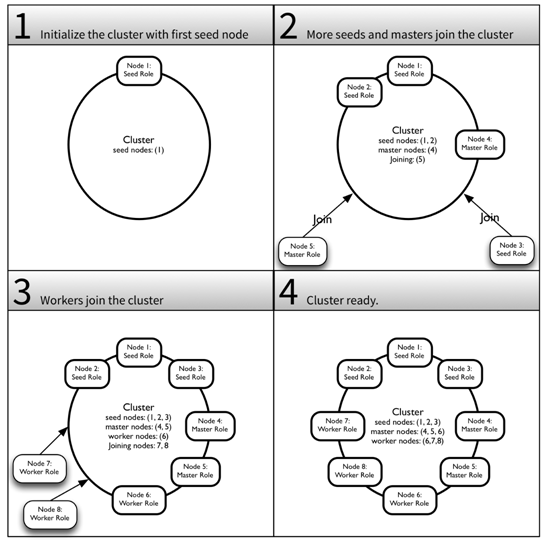
Let’s start by creating seed nodes using the REPL console, which will give more insight into how a cluster is formed.
To be clear, you wouldn’t go through these steps manually once you actually deploy a clustered application. Depending on your environment, it’s most likely that assigning addresses and starting the seed nodes in the cluster is part of provisioning and deployment scripts.
A node first needs to be configured to use the cluster module. The akka-cluster dependency needs to be added to the build file as shown:

![]() The build file defines a val for the version of Akka
The build file defines a val for the version of Akka
The akka.cluster.ClusterActorRefProvider needs to be configured in much the same way the remote module needed an akka.remote.RemoteActorRefProvider. The Cluster API is provided as an Akka extension. The ClusterActorRefProvider initializes the Cluster extension when the actor system is created.
Listing 1 shows a minimal configuration for the seed nodes (which can be found in src/main/resources/seed.conf).
Listing 1: Configuring the seed nodes
akka { loglevel = INFO stdout-loglevel = INFO
event-handlers = ["akka.event.Logging$DefaultLogger"]
log-dead-letters = 0 log-dead-letters-during-shutdown = off
actor {
provider =
"akka.cluster.ClusterActorRefProvider" #// Initializes
// the cluster module
}
remote { #// Remote configuration for this seed node.
enabled-transports = ["akka.remote.netty.tcp"]
log-remote-lifecycle-events = off
netty.tcp { hostname = "127.0.0.1"
hostname = ${?HOST} port = ${PORT} } }
cluster { #// Cluster configuration section.
seed-nodes = [ "akka.tcp://words@127.0.0.1:2551",
"akka.tcp://words@127.0.0.1:2552",
"akka.tcp://words@127.0.0.1:2553"
] #// The seed nodes of the cluster.
roles = ["seed"] #// The seed node is given a seed role
// to differentiate from workers and masters.
role {
seed.min-nr-of-members = 1 #// The minimum members of every role
// for the cluster to be deemed to be
// "up." In the case of the seed nodes,
// the cluster should be up once there
// is at least one seed node up.
}
}
}
| NOTE |
Keep the addresses exactly the same Be sure to use 127.0.0.1 when you follow along; localhost might resolve to a different IP address depending on your setup, and Akka interprets the addresses literally. You can’t depend on DNS resolution for the addresses. The value in akka.remote.netty.ctp.host is used exactly for the system’s address; no DNS resolution is done on this. The exact value of the address is used when actor references are serialized between Akka remote nodes. So once you send a message to the remote actor referred to by such an actor reference, it will use that exact address to connect to the remote server. The main reason behind not using DNS resolution is performance. DNS resolution, if configured incorrectly, can take seconds; in a pathological case minutes. Finding the cause for delays to be an incorrect DNS configuration is not easy or immediately apparent to most. Not using DNS resolution simply avoids this problem, but it does mean you have to be careful with configuring the addresses. |
We’ll start all the nodes locally throughout these examples. If you want to test this on a network, just replace the -DHOST and -DPORT with the appropriate hostname and port respectively, which sets the environment variables HOST and PORT. The seed.conf file is set up to use these environment values as overrides if they’re available. Start sbt in three terminals using different ports, inside the chapter-cluster directory. sbt is started for the first seed node as shown:
sbt -DPORT=2551 -DHOST=127.0.0.1
Do the same for the other two terminals, changing the -DPORT to 2552 and 2553. Every node in the same cluster needs to have the same actor system name (tt>wordsin the previous example). Switch to the first terminal, in which we’ll start the first seed node.
The first node in the seed nodes must automatically start and form the cluster. Let’s verify that in a REPL session. Start the console in sbt (by typing console at the sbt prompt) in the first terminal started with port 2551, and follow along with listing 2.
Figure 6 shows the result.
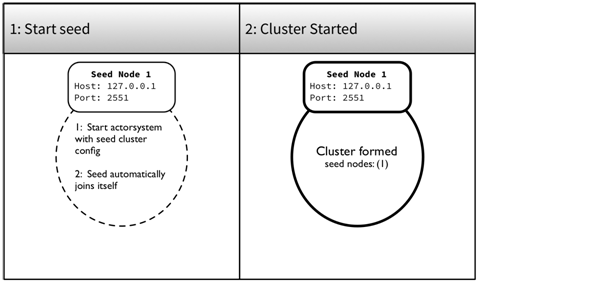
Figure 6: Startup the first seed node
Listing 2: Starting up a seed node
...
scala> :paste // Entering paste mode
(ctrl-D to finish)
import akka.actor._
import akka.cluster._
import com.typesafe.config._
// Load the configuration for the seed node, found in
// the filesrc/main/resources/seed.conf
val seedConfig = ConfigFactory.load("seed")
// Start the words actor system as seed node.:
val seedSystem = ActorSystem("words", seedConfig)
// Exiting paste mode, now interpreting.
// Remote and cluster modules are automatically started.
// The console output is simplified to show the most
// relevant messages.
[Remoting] Starting remoting
[Remoting] listening on addresses :
[akka.tcp://words@127.0.0.1:2551]
...
// The cluster name is the same as the name of the actor system.
[Cluster(akka://words)]
Cluster Node [akka.tcp://words@127.0.0.1:2551]
// The cluster name is the same as the name of the actor system.
Started up successfully
Node [akka.tcp://words@127.0.0.1:2551] is JOINING, roles [seed]
[Cluster(akka://words)] Cluster Node [akka.tcp://words@127.0.0.1:2551]
// The words cluster seed node has automatically joined the cluster.
Leader is moving node [akka.tcp://words@127.0.0.1:2551] to [Up]
Start the console on the other two terminals and paste in the same code as in listing 2 to start seed node 2 and 3. The seeds will listen on the port that we provided as -DPORT when we started sbt. Figure 7 shows the result of the REPL commands for seed nodes 2 and 3.
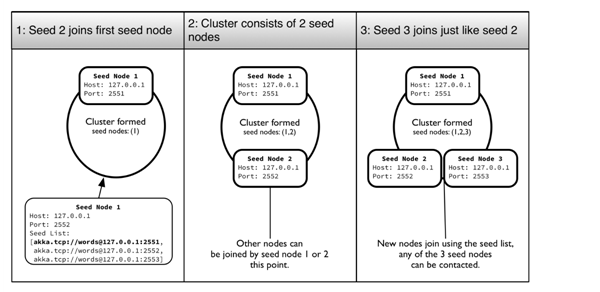
Figure 7: Start up the second seed node
You should see something similar to listing 3 in the other two terminals, confirming that the nodes joined the cluster.
Listing 3: Seed node 3 confirming joining the cluster
[Cluster(akka://words)] Cluster Node [akka.tcp://words@127.0.0.1:2553] // Output formatted for readability; will show as one line in the terminal - Welcome from [akka.tcp://words@127.0.0.1:2551]
Listing 4 shows the output of the first seed node. The output shows that the first seed node has determined that the two other nodes want to join.
Listing 4: Terminal output of seed node 1
// Output abbreviated and formatted for readability. [Cluster(akka://words)] Cluster Node [akka.tcp://words@127.0.0.1:2551] // The first seed node joins itself and becomes the leader. - Node [akka.tcp://words@127.0.0.1:2551] is JOINING, roles [seed] - Leader is moving node [akka.tcp://words@127.0.0.1:2551] to [Up] // Seed node 2 is joining. - Node [akka.tcp://words@127.0.0.1:2552] is JOINING, roles [seed] - Leader is moving node [akka.tcp://words@127.0.0.1:2552] to [Up] // Seed node 3 is joining. - Node [akka.tcp://words@127.0.0.1:2553] is JOINING, roles [seed] - Leader is moving node [akka.tcp://words@127.0.0.1:2553] to [Up]
One of the nodes in the cluster takes on special responsibilities; to be the leader of the cluster. The leader decides if a member node is up or down. In this case the first seed node is the leader.
Only one node can be leader at any point in time. Any node of the clusters can become the leader. Seed nodes 2 and 3 both request to join the cluster, which puts them in the Joining state. The leader moves the nodes to the Up state, making them part of the cluster. All three seed nodes have now successfully joined the cluster.
 |
Akka in Action: Why use clustering? By Raymond Roestenburg, Rob Bakker, and Rob Williams This article was excerpted from the book Akka in Action. |